概述
Hadoop自推出以后在互联网快速发展的背景下得到了许多公司的认可,已然成为大数据的基础处理平台甚至是行业标准。Facebook,Amazon,Yahoo等等公司都在自己的系统中构建了基于Hadoop的处理平台。除了最基本的数据处理功能,在Hadoop之上现在已经发展出来一套生态系统,应用最广泛的莫过于Hive和HBase了。在Hadoop之上构建的系统都直接或间接地使用了了Hadoop的分布式存储模块HDFS和计算模块MapReduce。
Mac下handoop 的安装
可以参考如下博客
hadoop 的基本组成
Hadoop的基本组成包含了分布式存储模块HDFS和计算模块MapReduce。
- HDFS
HDFS借鉴的是Google的GFS系统,是一个基于Key/Value的分布式存储系统。HDFS是为了大文件、一次写多次读的应用场景而设计的。所有要存储在HDFS中的文件需要按块(默认64M)切分,每个数据块有在不同的机器上(默认是本机,本机架,不同机架)有多个备份(默认为3份)。系统通过对失败机器数据文件的再分配、复制来自动保证文件的数据安全。HDFS并不适合大量小文件或者对写要求高的场景。这样,我们可以有个概念,Hadoop中处理的数据会分块备份三分存在不同的机器上。
- MapReduce
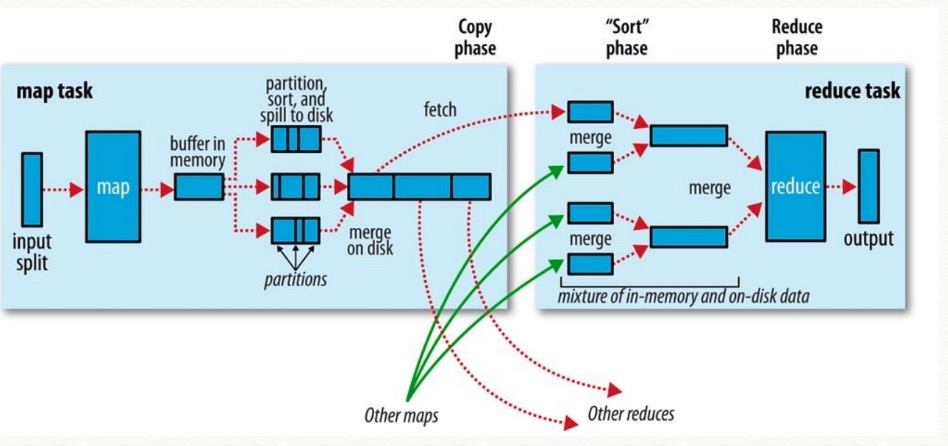
MR
MapReduce是Hadoop的数据处理模块,Hadoop对数据的处理都被抽象成Map和Reduce这两个函数的操作。
map
通常地,Map函数的工作是从HDFS中读取上输入文件,读入的数据是一个个(MapInputKey/MapInputValue)对,根据作业需求处理后输出一个个(MapOutputKey/MapOutputValue)对,后台的输出线程会把输出的文件按照MapOutputKey把对应的MapOutputValue合并起来(MapOutputKey–>MapOutputValue0,MapOutputValue1,…),同时还会将输出按照MapOutputKey排序(注意,每一个Map都会有同样的样的输出,不同的Map会有同样的Key值输出)。逻辑上,我们可以将不同Map输出的同一个Key的数据合起来看做一个小Partition(Finer Partition,FP)
reduce
reduce函数则是对map提取出来的数据进行处理。
- 具体的一个mapReduce job 执行过程,下图还是很清楚的

mapreduce 的执行过程是有中间数据落地的,也就是内从和磁盘来回交换数据,以后会有Spark的介绍,其中Spark执行一个MapReduce操作数据是不落地的所有数据都会被拉进内存执行操作。



